
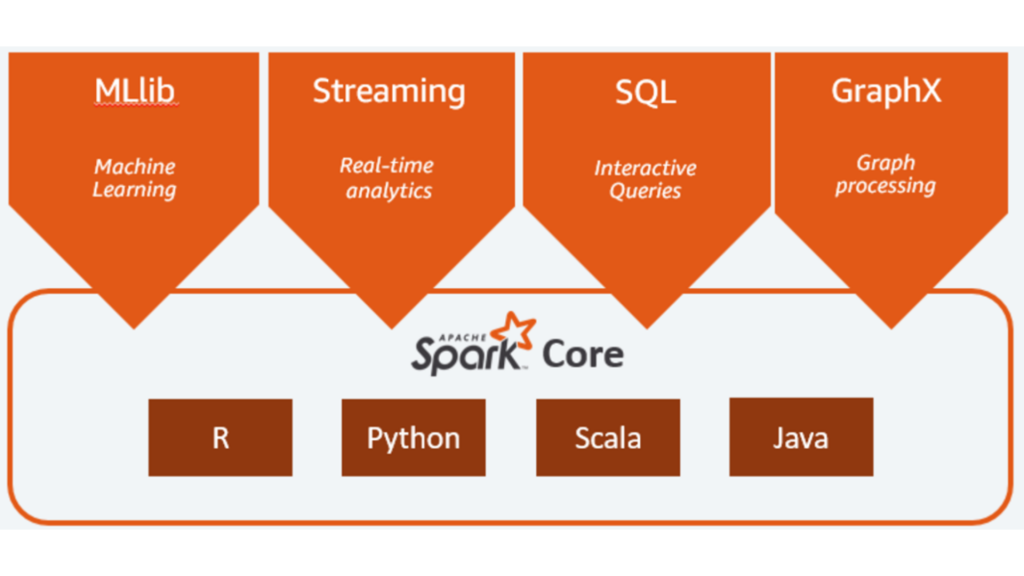
Apache Spark is a unified computing engine and a set of libraries for parallel data processing on computer clusters. Spark is one of the fastest and hot areas in the Hadoop ecosystem for managing massive amounts of data in an extensible way. There are really excellent features built on top of Spark like things for Machine Learning, Graph Analysis, Streaming data, and all other types of really cool stuff. Spark supports multiple widely used programming languages (Python, Java, Scala, and R), includes libraries for diverse tasks ranging from SQL to streaming and machine learning, and runs anywhere from a laptop to a cluster of thousands of servers. This makes it an easy system to start with and scale-up to big data processing or incredibly large scale.
What is Spark ?
According to Apache, “Spark is a general engine for large scale data processing “ …
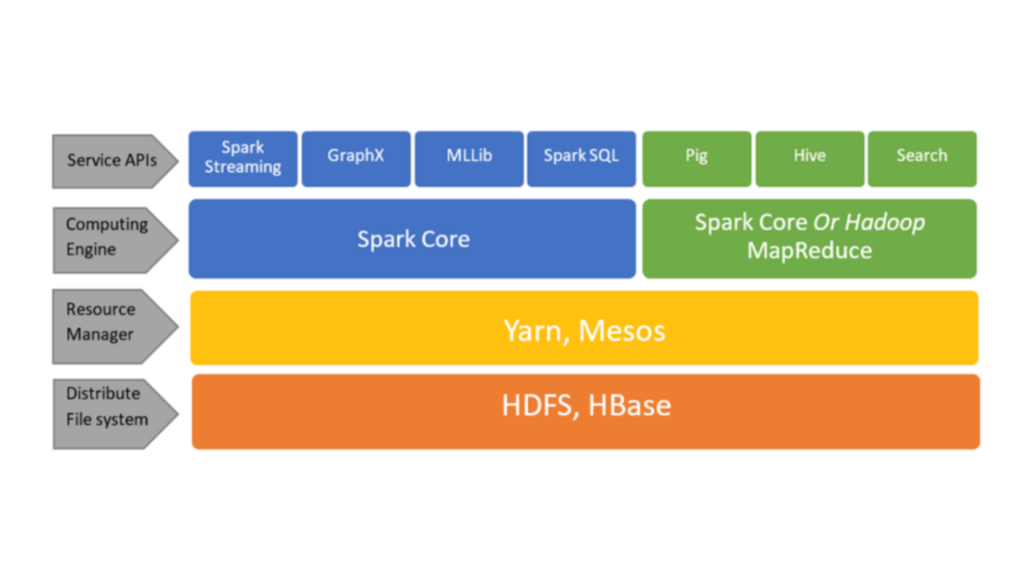
Above definition is not terribly specific, we can say the above words for about the entire Hadoop ecosystem. But Spark does take it to a new level, it gives lots of flexibility, allows writing real programs using Java, or Scala, or Python to do complex manipulation of sets of data. What sets it apart from Pig or Hive is that it has a rich ecosystem for Machine Learning, or Data Mining, or Graph Analysis, or Streaming Data. Essentially is a very powerful, scalable and extensible framework.
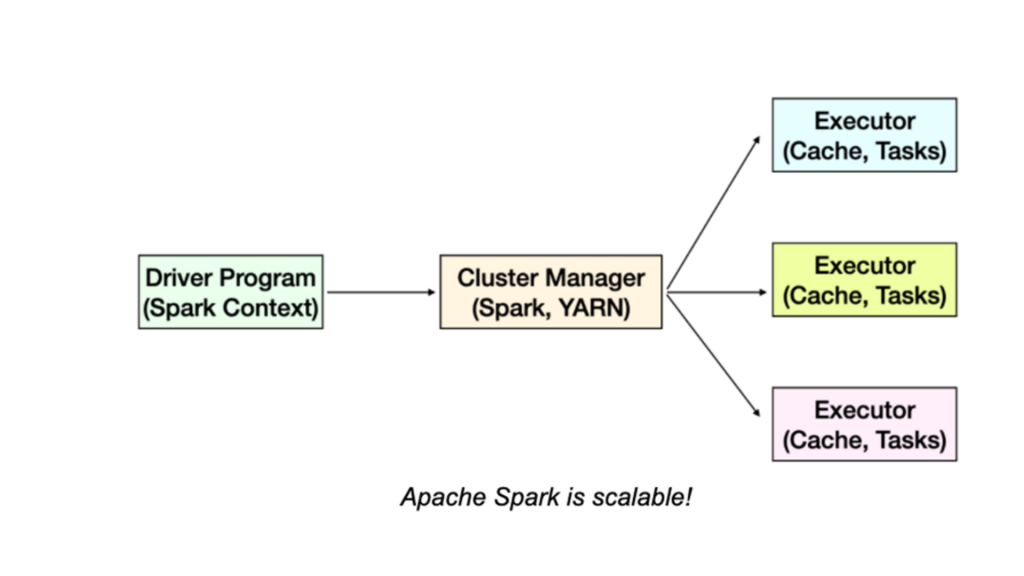
Just like any Hadoop based technology, Spark is scalable. Sparks follow the same pattern, where we will have a driver program that controls what is going to happen in your job, and that goes through some sort of cluster manager. We can use YARN (Yet Another Resource Manager), but that’s’ only one option. Spark can run on Hadoop. It can run on its own cluster manager which is built in or it can use another popular cluster manager called Apache Mesos.
But whatever cluster we choose, the cluster manager will distribute the job across a set of commodity computers, processing the data in parallel. Each executor has some sort of cache and tasks it will be responsible for. Cache is actually the key to the performance of Spark. Unlike disk based solutions, say Hadoop, instead of hitting HDFS all the time, Spark is a memory based solution. It tries to retain as much as it can in RAM as it goes. This is the one of its keys to the speed. Another key to Spark is speed is directed acyclic graphs.
- When compared with MapReduce, Spark is 100 times faster and is about 10 times faster when limited to only disk access.
- In built Directed Acyclic Graph (DAG) to optimize the workflows. Just like Tez, Spark has DAG which allows the fastest way to get to a solution within a workflow.
- Spark is used across the board by the largest of technology, finance, life sciences, manufacturing, retail, transportation industries to name a few. They are solving real world problems with real massive data sets using Spark.
- Spark developers code in Scala, Java, or Python. Spark itself is written using Scala. But one can effectively use Java or Python to code for Spark. Few lines of code can kick off very complex analysis under a cluster using Spark.
- Spark is built around the main concept Resilient Distributed Dataset (RDD). It is basically an object that represents a dataset, and there are various functions we can call on RDD for transformation, or reduce, or analyze in whatever way we want to produce new RDD’s. Usually we are writing a script that takes RDD of input data and transforms it into whatever way we want as we process.
- Since Spark 2.0, we have Dataset which is an abstraction at top of RDD. Dataset is more of a SQL approach to RDD.
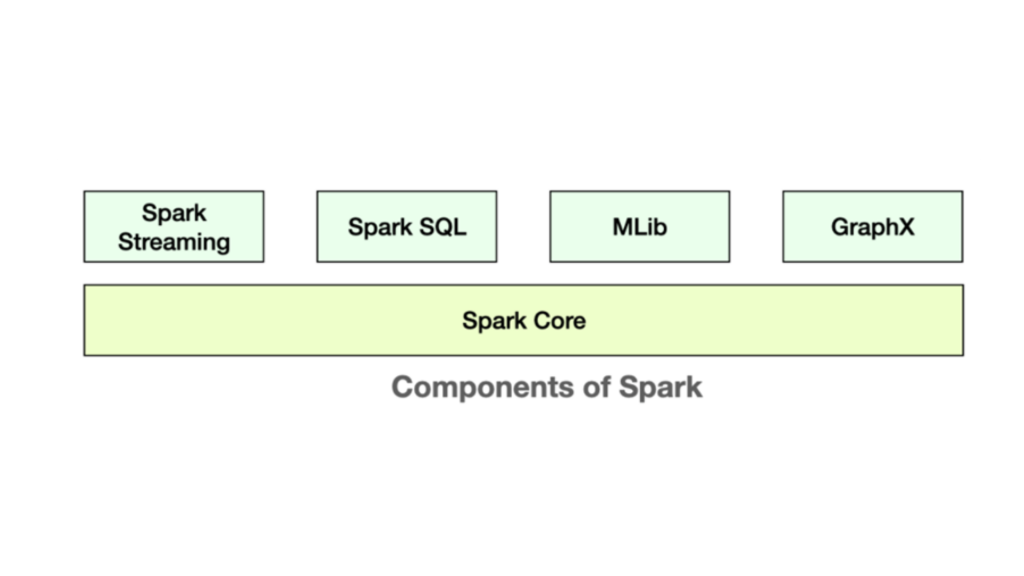
Spark is very rich in components. Besides Spark core, there are also programs at top of core to help facilitate development. Spark Streaming, for example, allows real time streaming and processing of data instead of batch processing. Imagine you have a fleet of web servers producing logs, those logs can be ingested as it is being produced. Logs can be analyzed against some window of time and processed in real time, or dispatched to SQL or NoSQL databases for further analysis or visualization in some visual tool like Tableau.
Spark SQL, it is extremely popular these days, and is basically SQL interface to Spark. For programmers familiar with SQL, they can easily write SQL queries into Spark, or they can write SQL like functions to transform datasets to Spark. These functions are called Datasets and its general direction where Spark is enhancing.
MLib is an entire library of machine learning and data mining tools that we can run on Datasets. Using this we can break a machine learning problem of clustering, or regression analysis into mappers and reducers. MLib does all this hard work for us. We can create high level classes for extracting meaningful information.
GraphX can help to build, for example, social network graphs. A graph of friends of friends and analyze the properties of that graph to find relationships and connections. Find out the shortest paths, say degree of separations.
In short, very rich ecosystems around Spark which allows us to do a wide variety of tasks on Big Data across a cluster. This is why Spark is one of the most popular and exciting areas of Hadoop.
Resilient Distributed Data Sets (RDD)
RDD is the core of Spark. It is an abstraction of all magic that happens under the hood of Spark Core. This makes sure that a given job is equally distributed across clusters, that it can fairly handle in a resilient manner, and eventually looks like a Dataset. So these RDD objects are a way of storing keys and value information. To make RDD’s we use something called SparkContext.
SparkContext is the environment within which we are running RDD’s. The RDD is created by a driver program of SparkContext. SparkContext is responsible for resiliency and distribution. We can use Spark shell which creates a “sc” object for us or we can create a spark object from a standalone script that we can run on a scheduler. Essentially SparkContext is what creates RDD that we start with.
Creating RDD can be done in several different ways, for example, if we want to create an RDD of numbers that parallelize sequence of numbers such as:
nums = parallelize([1,2,3,4])
This will create RDD “nums” with given value of 1,2,3,4 and now we can act upon the nums RDD. But in reality, this data is too small, we to create a RDD, we load may load a text file from local or cloud drive, such as:
sc.textFile(“file:///c:/users/myname/ALargeTextFile.txt”)
Or
sc.textFile(s3n://, hdfs://)
We can use URL or even cluster of HDFS infrastructure to load a file as RDD that will contain a line of text in every row of RDD. We can also create RDD from Hive context as shown:
hiveCtx = HiveContext(sc)
rows = hiveCtx.sq(“Select name, age FROM users”)
This way we can do SQL queries from within Spark. Besides you can create RDD from any database such as Cassendra, JDBC, HBase, Elasticsearch, JSON, CSV, sequence file, object files, and various compressed formats. Basically from any datasource that Hadoop supports.
Transforming RDD’s
There are various RDD operations that can be executed based upon business requirement, listed as:
- map
- flatmap
- filter
- distinct
- sample
- union, intersection, subtract, cartesian
Once we have RDD, we can think in terms of mappers and reducers. We can use “map”, which will apply some function transforming rows and columns creating a new transformed RDD. Map is used when we have one to one relationship , so as one input row is mapped to one output row RDD. But sometimes we may need many rows to converge into one row, “flatmap” performs that for us. Or maybe we want to split an input line into multiple rows, we can use flatmap. Another scenario where flatmap may be used is if we want to discard some of the input line. In short, “map” can have only a one-to-one relationship between input lines and output rows, while “flatmap” can have any type of relationship.
Another important operation is “filter”, which as the name implies, can implement filters on the input and produce funneled RDD. Next, “distinct” gives unique values from a given input. If we want a randomized input, we can apply a “sample” function to produce random RDD. Finally, we can combine RDD’s together using “union”, or “intersection”, or “subtract”, or “cartesian”.
All the above can be done using Pig or Hive, Spark is just a little bit more powerful and popular.
For example, let’s say we want to take an RDD of integers as input and square them. All we do is use SparkContext (sc) object, parallelize the number to create a simple RDD that contains the value i.e. each row has one column.
myrdd = sc.parallelize([2,4,6,8,10])
squarerdd = myrdd.map(lambda x : x * x)
Second line above is saying take each input row from myrdd, call it x, and then return the value x2. This will output sequence 4, 16, 36, 64, 100 essentially squares of the input. Looks pretty trivial but the concept here is defining the function inline, taking the value as input, processing,
and outputting in the same line. We are inputting a lambda function as input to the map function of Spark. This is a simple example of functional programming i.e. we are defining functions that can transform inputs and specify them as arguments to other functions.
This dataset is quite small, but imagine extremely large dataset of similar nature as input, Spark can get us the output at lightning fast speed.
There are more things we can do with RDD essentially transform them into something else, for example, what if we want to reduce inputs ? These are called RDD actions. Here are few examples of RDD actions:
- collect : it will take all input of RDD and condense into a driver script as python object
- count: as name suggest, will give number of rows in the RDD
- countByValue: return tally by each unique value and count of those values
- take: this can return say top 10 results of RDD
- top : same idea as take, top few rows of an RDD (useful for debugging)
- reduce : allows to combine all the values associated with a unique key (similar to map reduce)
- There are more actions…
In Spark nothing actually happens unless one of the above actions is called upon an RDD. Before this, all Spark is doing is building a chain of dependency internal graph, but not taking any other action. Only when action is called, then Spark figures out the quickest graph through those dependencies and it is at that point it kicks off the job on a cluster. This could be confusing at first as we debug our program, but as we go along and call the actions, the nature of Spark becomes much clearer. This is one of the main reasons for the speed of Spark.